|
 EPD: The Eukaryotic Promoter Database. EPD: The Eukaryotic Promoter Database.
The Eukaryotic Promoter Database is an annotated non-redundant collection of eukaryotic POL II promoters, for which the transcription start site has been determined experimentally. It provides information about eukaryotic promoters available in the EMBL Data Library and is intended to assist researchers in the investigation of eukaryotic transcription signals.
|
|
 MGA: Mass Genome Annotation Archive. MGA: Mass Genome Annotation Archive.
MGA is a repository of publicly available so-called mass genome annotation data (ChIP-Seq and RNA-seq) for several model organisms. It also hosts a large collection of so-called derived data such as ChIP-seq peaks, genome annotations (e.g. promoters, splice-junctions, etc.), and sequence-intrinsic data (conservation scores, SNPs, indel, etc.).
|
|
 UCNEbase: A database for ultraconserved noncoding elements and genomic regulatory blocks. UCNEbase: A database for ultraconserved noncoding elements and genomic regulatory blocks.
UCNEbase provides information on the evolution and genomic organization of ultra-conserved non-coding elements (UCNEs) in multiple vertebrate species. It currently covers 4351 such elements in 18 different species.
Around half of these elements are located within intergenic regions (2'139) and the rest are located within non-coding parts of genes: introns (1'713) and UTRs 499). The majority of UCNEs are supposed to be transcriptional regulators of key developmental genes.
|
|
|
ChIP-Seq: The ChIP-Seq Analysis server.
The ChIP-Seq Web Server is a comprehensive online resource for analysing ChIP-Seq data and other types of mass genome annotation data RNA-seq, DNA-methylation and sequence-derived features). The most common analysis tasks include positional correlation analysis, peak detection, and genome segmentation.
|
|
 SSA: The Signal Search Analysis server. SSA: The Signal Search Analysis server.
SSA is a software package and a Web interface for the analysis of sequence motifs that occur at constrained distances from functional sites, such as transcription initiation sites or transcription factor binding sites. The possible analysis includes motif occurrence profile plots, generation of a signal list, generation of constraint profiles, pattern optimization as well as finding motifs around functional sites.
|
|
 PWMTools: Position Weight Matrix model generation and evaluation tools. PWMTools: Position Weight Matrix model generation and evaluation tools.
PWMTools is a Web interface for Position Weight Matrix (PWM) model generation and evaluation. It includes the following tools: MSeq which is a software pipeline used to derive TFBS models from DNA sequences such as HT-SELEX and MITOMI-seq, PWMEval and PWMScore that are tools used to evaluate PWM models based on ChIP-seq data, and PWMScan which is a tool to scan entire genomes of common model organisms with a PWM.
|
|
 SNP2TFBS: Mapping SNPs to Transcription Factor Binding Sites. SNP2TFBS: Mapping SNPs to Transcription Factor Binding Sites.
SNP2TFBS is a Web interface aimed at studying variations (SNPs/indels) that affect transcription factor binding (TFB) in the Human genome.
|
|
|
 HTPSELEX: A database of in vitro selected TFBS sequences obtained with high-throughput SELEX. HTPSELEX: A database of in vitro selected TFBS sequences obtained with high-throughput SELEX.
The HTPSELEX database contains sets of in vitro selected transcription factor binding site sequences obtained with the high-throughput SELEX (HTPSELEX) method. In addition, the database also contains binding sites obtained with conventional SELEX method.
|
|
 TagScan: Online tool for finding short exact matches in large sequence databases. TagScan: Online tool for finding short exact matches in large sequence databases.
TagScan allows searching for perfect matches and for single or double nucleotide mismatches between oligonucleotide queries of up to 60 bases and sequence databases comprising entire genomes or mRNA reference sequences. The smallest query allowed is 10 nucleotides long.
|
|
 ZFN-Site: Genome-wide tag scanner for nuclease off-sites. ZFN-Site: Genome-wide tag scanner for nuclease off-sites.
Based on the TagScan tool, this application is intended to search genomes for specific target sites and off-target sites, such as for pairs of zinc finger proteins (ZFPs), zinc finger nucleases (ZFNs) and modified homing endonucleases. This can either define a zinc finger nucleases (hetero-dimer) or allow for homo-dimers depending on the status of the checkbox in the input form.
|
|
|
 TROMER: Transcriptome Analysis Database. TROMER: Transcriptome Analysis Database.
The transcriptome analyser (TROMER) project provides tools to determine and document all the transcribed elements of a genome. The transcriptome data include transcribed regions, splice variants, SAGE mappings, MPSS mappings, Affymetrix chips mappings, etc., for several organisms.
|
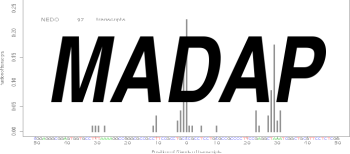 MADAP: Clustering tool for one-dimensional genome annotation data mapped onto genome sequences. MADAP: Clustering tool for one-dimensional genome annotation data mapped onto genome sequences.
MADAP identifies groups of data corresponding to one or several genomic sites, and estimates the volume and extension of such groups (clusters). Input data might be obtained from cDNA and tag sequencing protocols to map the 5' and 3'ends of mRNA, from ChIP-chip analysis, or from genome-wide SNP-typing.
|
|
|
|
